- Definition in Road Network
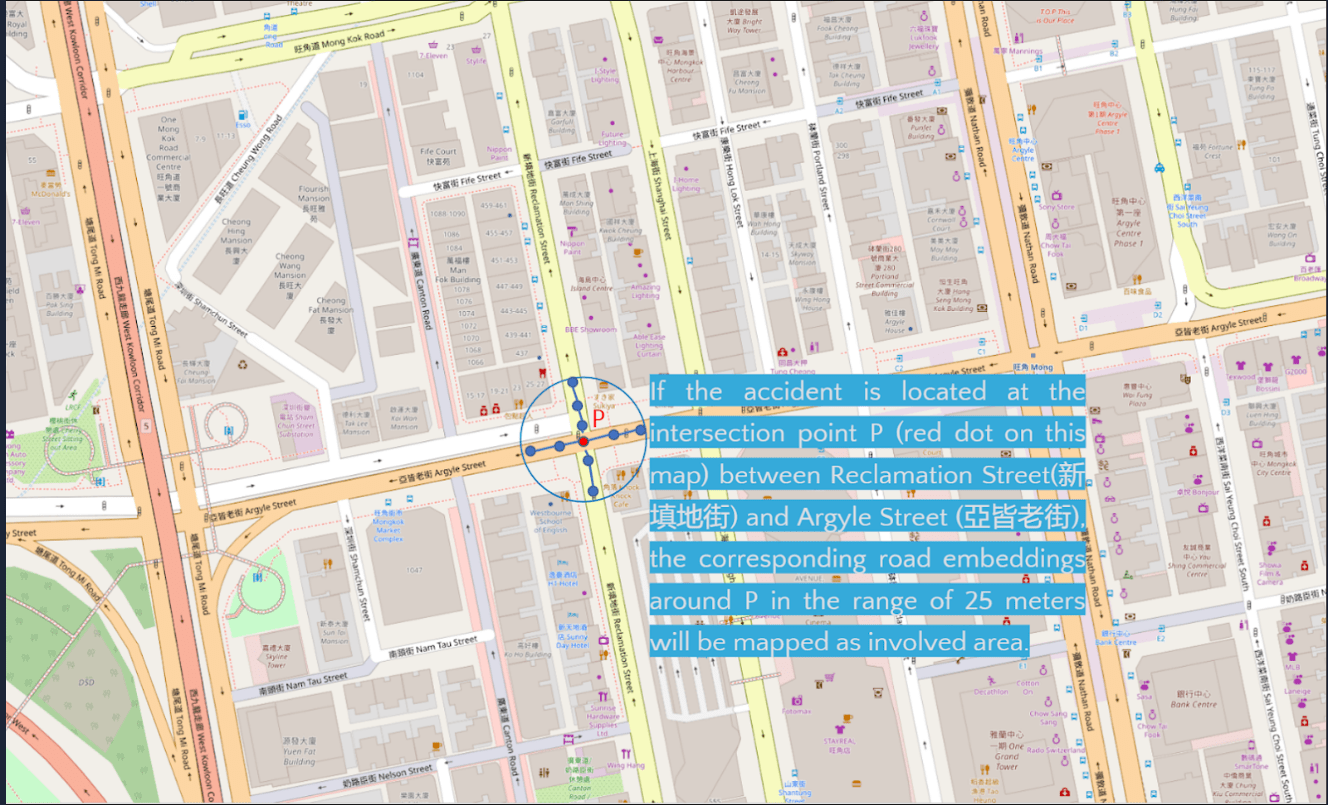
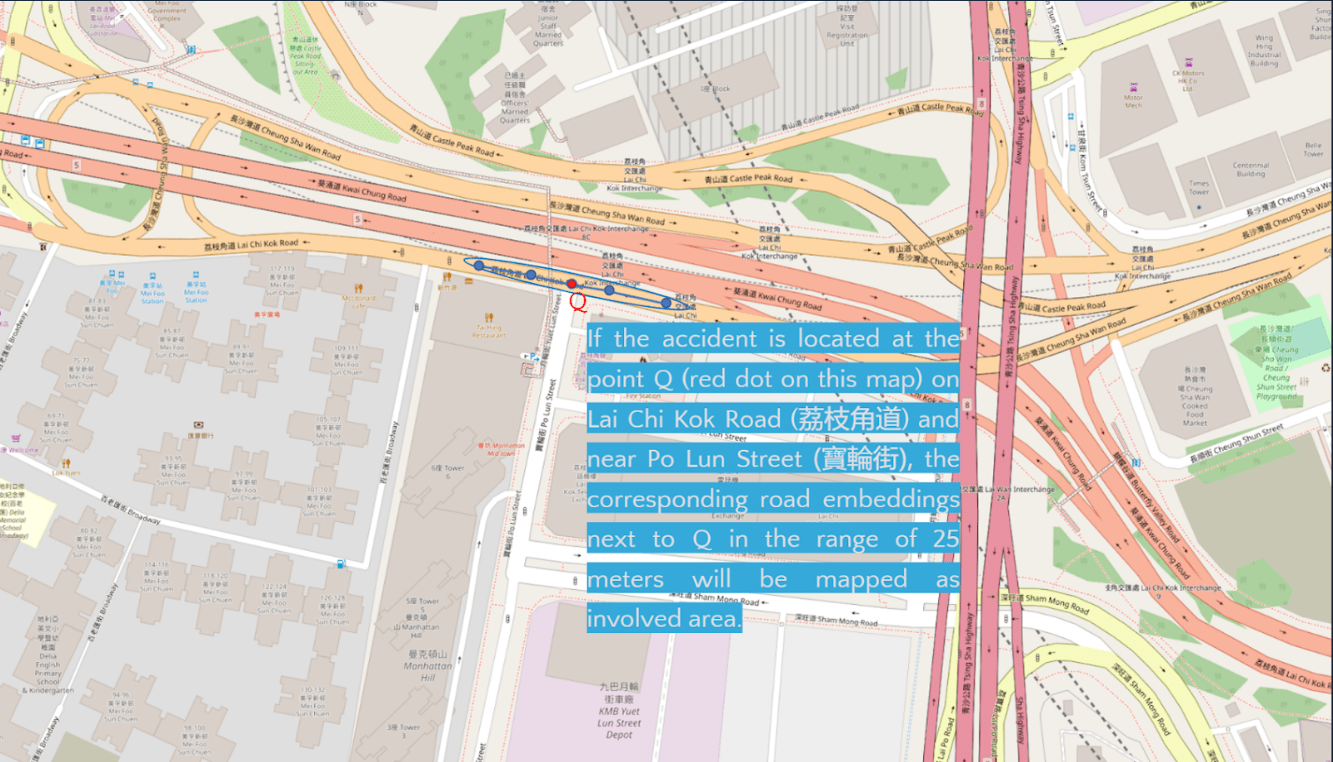
Typically, a road network is modeled as a directed graph, which contains intersections or points of location as nodes as well as road segments as edges. What is more, both nodes and edges consist of not only the geospatial information such as the coordinates, but also the information of road network structure, road installations and road characteristics like traffic signals, number of lanes, and road types. This information could be useful for predicting the accident proneness of a location.
- Deep Learning and Feature Extraction
Extracting useful or effective latent features is difficult and complicated for machine learning. Feature engineering often requires a lot of time but is not effective in finding the hidden features. Deep learning can extract the latent features from simple features to form more abstract high-level representations to find the distribution of data-style feature expression by combining low-level features (Alex Krizhevsky et al., 2017).
- Graph Embedding for extracting the structural information from a graph or network
As stated in point 1, a road network is commonly modeled as a directed graph including a set of nodes and edges, and a directed road segment or an edge is allowed to travel from a start node to end node generally. Such graph representations make graph embedding methods such that it could be extracting structural information or features from road networks. In graph embedding, it is supposed to build a model to learn the representations which embed nodes in networks into a d-dimensional vector space in a way that the nearby nodes of the self node in the network are mapped to feature vectors encoding the structural information of the graph (Tobias Skovgaard Jepsen et al., 2018). Simply put, graph or network embedding can extract the structural information in networks and form a representation of the self node.
- Node2vec for learning intrinsic properties of a road network structure of a node
Node2vec, which is a deep learning or graph embedding technique, is used in this project. It learns useful latent feature vectors or embeddings of the road network structure as inputs to machine learning or data mining algorithms. In addition, node2vec aims to learn node embeddings but attach importance to the issue of sampling the network neighborhood relationship by applying parameterized random walk instead of uniform random walk. The two parameters are parameter p in and out parameter q, controlling the walking process by the probability of returning back to the previous node, or selecting the next node away from the previous node in order to simulate Breadth-First Search and Depth-First Search respectively (Aditya Grover & Jure Leskovec, 2016). In other words, the trained node2vec model can generate a node embedding, which represents the node capturing intrinsic properties of road network structure, that is the probabilities of reaching the corresponding nodes in random walks of the self node. At the end, by checking the structure similarity or the probabilities between self node and other nodes, node2vec can do clustering so that the similar nodes will be grouped together as one group.
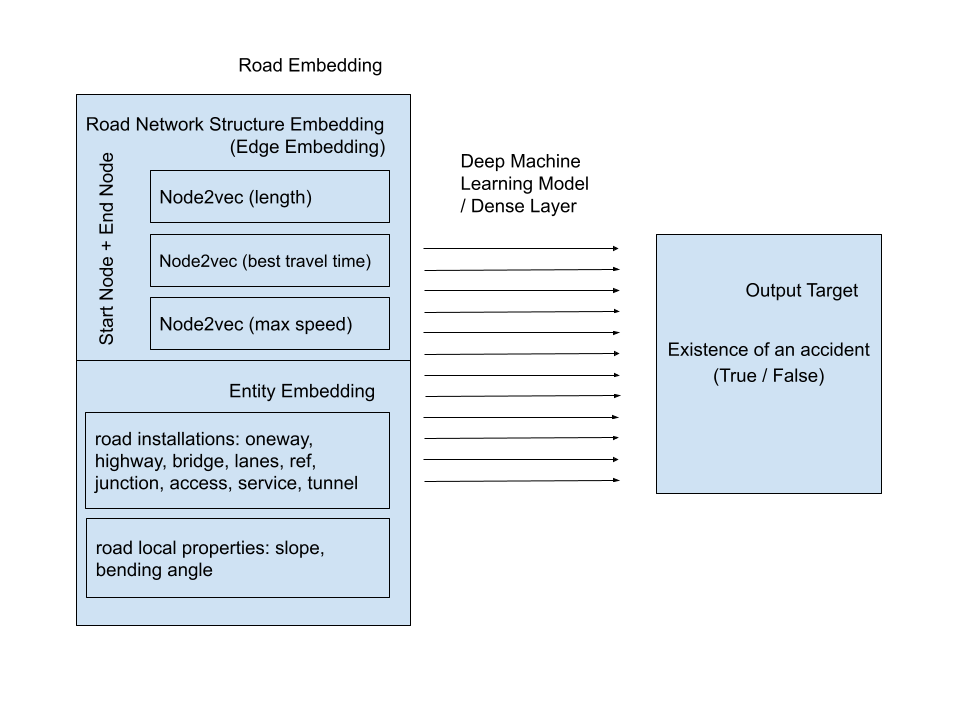
Node2vec can learn a node embedding, but an edge can be embedded by aggregating the embeddings of the start node and end node of the edge. By concatenating the embeddings of its start node and end node, that edge embedding could be represented as a road segment in the network. (Tobias Skovgaard Jepsen et al., 2018)
- Neural Network in the prediction of accident proneness from road infrastructure design
A Neural Network consists of many simple and connected processors called neurons (Schmidhuber, J., 2015). It mimics the operation of the human brain. Neural Networks can adapt to changing the input to perceive the environment by activating the input neurons. Other neurons get activated through weighted connections from previously activated neurons. Through the backpropagation, the loss of the model will be minimized. Therefore, a neural network can learn the rules of the model itself instead of hand-crafting. Artificial Neural Network (ANN) or the dense layer is based on this concept. Our classifier (deep machine learning model) is the dense layer. After inputting the road network structure vectors, road installations and local properties (e.g. slope and bending angle) into the classifier, the proneness of accident will be outputted.
- Classification in the deep machine learning model
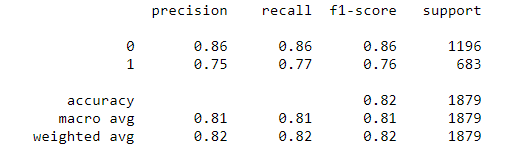
There are several machine learning models that can be used in Classification. In this project, we use a variant of logistic regression. In logistic regression, a linear equation with optimized coefficients is to be found to give a decision boundary which can be used to classify the featured data into 2 classes. Then, the linear equation is transformed by the sigmoid function and its output is between 0 and 1 which is a probability value that maps to different classes. Logistic function can be described as P(Z) = expZ/(1+expZ). P behaves like the distribution function of a symmetrical density, with mid-point zero; as Z moves through the real number axis, P rises monotonically between the bounds of 0 and 1. (J.S. CramerIt, 2002). It uses cross entropy as a loss function and minimizes the loss function by gradient descent. In order to increase accuracy of the result, we use keras deep learning model which contains 10 input layers and 11 dense layers and the output layer is softmax. Different from logistic regression, we can adjust the number of neurons of the hidden layer which is more flexible for us to construct a more complex deep learning model.
- Web Crawling for extracting accident news
The graph embeddings for predicting traffic accident blackspots need lots of data to do the data analysis. The public is the user of the road, so the source of the traffic accidents should come from the daily life of the people. Therefore, the news of traffic accidents that happen every day is the closest data used for analysis. Also, the news contains much useful information about traffic accidents, such as location, time, and so on. This information can also be used to extend and analyze with other data.
Web crawling is a tool that can crawl the content of the target website automatically. This can help collect an amount of news of traffic accidents from different news websites. The appropriate data that needs to be used as analysis data is to be defined before starting to collect the data from various websites, such as which types of news are suitable as sources. Afterward, search and filter the source of the news of different websites from the search engine. Then, define the depth and the breadth of the news. For example, the range of the time of the news (the past ten years traffic accidents news) and the detail of the news (severity of the traffic accidents), etc. A focused crawler is one of the methods of crawling, which is a web crawler that collects Web pages that satisfy some specific property, by carefully prioritizing the crawl frontier and managing the hyperlink exploration process (Chakrabarti, Soumen, et al., 1999). The crawler can focus on crawling the specific time range for the news of traffic accidents. The raw data can be stored in databases after getting it from news websites. Finally, clean the dirty data in the databases to build a new dataset, and extract the content and the details from the new dataset for the data analysis.